


The use of agentic systems is becoming the go-to when automating complex tasks. As a data scientist, you need to keep up and learn the new paradigm of automation, one in which natural language becomes the primary interface for computation. Once you have seen this new concept, you will realize that the real challenge is an engineering problem: creating reliable, structured, and reproducible systems around probabilistic models. The goal is to learn how to design agentic systems that can reduce repetitive cognitive workload and assist with human tasks more efficiently and consistently.
Throughout this blog, you will learn about the emerging concept of the LLM Operating System (LLMos), in which the language model serves as the central reasoning engine, orchestrating tools, memory, retrieval, and multiple specialized agents. Then you will dive into the real, practical designs to build trustworthy agentic pipelines. By the end, you will have built your own lightweight multi‑agent system using the Python library LLMlight that runs locally and privately, using structured prompts, retrieval‑augmented generation, embedding‑based search, and specialized agents that collaborate to solve complex tasks.
If you found this article helpful, you are welcome to follow and subscribe because I write more about Data science! I recommend experimenting with the hands-on examples in this blog. This will help you to learn quicker, understand better, and remember longer. Grab a coffee and have fun!
An Introduction Towards Agentic Systems.
I started writing a brief introduction about agentic systems, but there are so many concepts that need to be explained, so it has become a larger introduction to agentic systems. I highly recommend not skipping this introduction because these new concepts are fundamental for designing agentic systems.
As a data scientist, there is great pleasure in building your own system instead of only consuming them. Nevertheless, we should always be cautious of the so-called “not invented here syndrome.” This describes the tendency of engineers to rebuild technology or software simply because it provides a complete understanding of how everything works from start to finish. While this can sometimes lead to unnecessary reinvention, it is also an important step when learning new technologies, especially in emerging fields such as AI agents. By experimenting and building these systems yourself, you will get a much deeper understanding of how they fundamentally operate, making it easier to see the advantages and the limitations of agentic workflows.
By building agentic systems yourself as a learning step, you will gain deeper understanding of how such systems fundamentally operate, making it easier to see the capabilities and the limitations.
Once you move beyond the chat prompt of ChatGPT, Gemini, and Grok and start building systems around these language models, you quickly realize that the real challenge is not generating text. The real challenge is designing workflows that can reliably solve practical problems in a structured and reproducible way. This creates enormous opportunities for organizations and researchers alike in tasks such as summarizing documents, generating reports, extracting information, analyzing text, and reasoning over large collections of data.
Tasks that once required carefully rule-based engineered systems can now often be handled using natural language instructions. Yet the reality is more complicated. The core challange remains similar; we need to design agentic workflows that are reliably, structured, and provide reproducible results.
Traditional deterministic systems are often very stable. Once deployed, they behave predictably unless the underlying rules are changed. Language models are different. Their outputs may vary depending on the prompt, the model version, parameter settings such as temperature, the context window, or even small wording changes. This flexibility is exactly what makes them powerful, but also what makes them difficult to control in production environments.
Takeaway 1: Your LLM is Not a Writer; It’s a CPU.
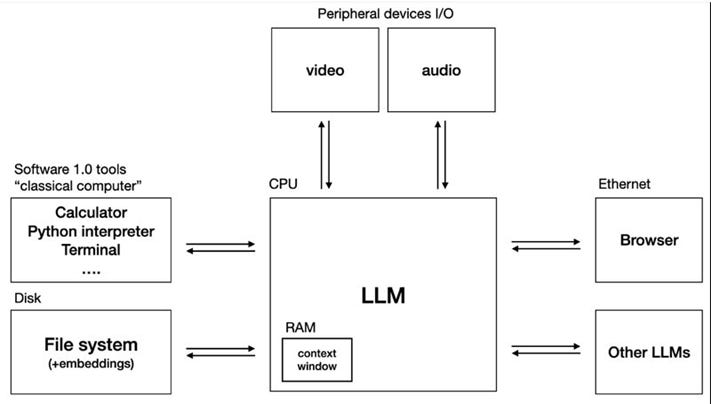
We are now entering a new computing paradigm where the large language model itself becomes the computational core of the system. Many similarities can be found with classical operating systems around hardware abstractions. Modern AI systems revolve around what can be described as an LLM Operating System (LLMos): an architectural design in which the language model acts as the central reasoning engine that orchestrates multiple tasks, tools, and agents. The LLMos term is coined by Andrej Karpathy [1, 2], and an architecture scheme is presented like this:
The analogy with traditional computing is surprisingly intuitive:
CPU → Large Language Model (LLM)
Bytes → Tokens
RAM → Context Window
Instead of executing deterministic instructions on bytes, these systems now operate probabilistically on tokens. The context window functions as a temporary working memory, retrieval systems act as external memory storage, and prompts increasingly resemble software interfaces between components.
We are entering a new computing paradigm where the large language model itself becomes the computational core of the system.
In many ways, we are now using language models like we did when designing entirely new software architectures, and this is challenging. The reason is that when we try to use language models for complex tasks, they require multiple forms of reasoning simultaneously. What we want in a single prompt is:
Retrieve information,
Reason over documents,
Validate structure,
Provide feedback,
Maintain consistency,
and finally generate a coherent final response.
Trying to solve everything in one large prompt becomes messy and unreliable. This is exactly where AI agents enter the stage. Instead of asking one massive model to solve an entire problem at once, agentic systems decompose the task into smaller, specialized subtasks. Multiple agents can then work together toward a shared objective, where each agent focuses on a specific responsibility. One agent may retrieve information, another evaluates quality, another structures references, while another summarizes the final output.
Using agentic systems, we do not solve the entire puzzle at once, but decompose it into smaller, specialized subtasks where multiple separate LLMs (aka the agents) can work on.
Takeaway 2: You Don’t Need More Billions of Parameters; You Need a Specialized “Agentic Team”.
The idea of building agentic systems sounds straightforward, but it introduces an entirely new set of engineering challenges:
How do agents communicate?
Which tasks should be deterministic and which stochastic?
How do we manage limited context windows?
How do we retrieve and statistically test for relevant information?
How do we prevent hallucinations?
How do we maintain consistent scoring and evaluations?
These questions are stressed even more when working with local, smaller models. Smaller models provide advantages in privacy, portability, and cost, but they also come with constraints: smaller context windows and reduced reasoning capabilities compared to larger cloud-based systems.
One of the most important realizations you may have when you do the hands-on part in this blog is that success rarely comes from a single clever prompt when building agentic systems. In practice, good systems are the result of carefully designed pipelines: chunking strategies, retrieval systems, embedding models, ranking mechanisms, structured prompts, scoring workflows, and specialized agents working together. This means that you also need to understand these concepts to make a real success of your (personal) project.
In the next sections, we will take a practical engineering approach to building an agentic system. We will walk through a real-world multi-agent architecture where we will set up multiple agents discussing and working together. Along the way, we will cover:
Retrieval-Augmented Generation (RAG),
Chunking and embeddings,
Local versus global reasoning,
Scoring workflows,
Instructions,
and the practical limitations of using local language models.
The Real-World Problem: Human vs. Machine.
Many real-world problems appear straightforward until you try to automate them with large language models. You may also have experienced that in your own line of work. The most common task to automate is the evaluation of documents. At first glance, the workflow seems simple: 1. Upload a document, 2. Ask a question, and 3. You wait and let the model generate an answer. However, in practice, these tasks are rarely isolated or deterministic because you likely have to ask multiple questions, provide more context, stop the model from hallucinating, and perform fact checks. The bad part, before you get a satisfying result, you run out of your free tokens.
The Monolithic Prompt is a Trap.
Even a single document can require multiple forms of reasoning. The complexity grows rapidly when documents become larger and more interconnected. Furthermore, there are large differences in reports, legal documents, scientific papers, technical specifications, policy documents, and research proposals. Relevant details are differently organized across these documents, terminology is inconsistent, and important conclusions may depend on relationships between multiple parts of the text.
As humans, we use our domain knowledge and expertise to navigate through the documents. We are aware of the company rules and can solve tasks naturally by continuously switching between local and global reasoning. As an example, we zoom into specific details when necessary, while still maintaining an overall understanding of the document as a whole. Language models, however, do not inherently reason this way. They process text through a limited context window and generate outputs probabilistically, token by token. The “monolithic” approach, or in other words, processing an entire objective into one pass, is a recipe for architectural pain. Such “one-shot” approaches suffer from various limitations. Let’s jump to the next section, where we will go into more depth on why single prompts fail on complex tasks.
Why Single Prompts Fail and Agentic Systems Work.
When you have access to a large language model chat interface, it is tempting to solve problems in the simplest possible way: feed an entire document into a LLM and ask it to evaluate the content in one go. This monolithic approach has four core limitations when solving large, complex tasks. Let me break it down:


