
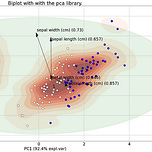

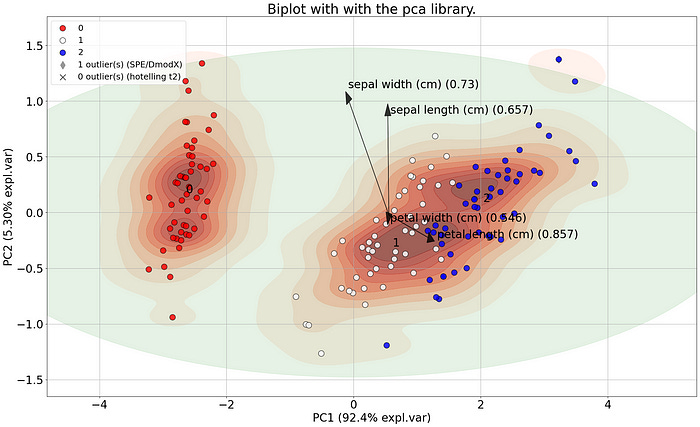
Principal Component Analysis is the most well-known technique for (big) data analysis. However, interpretation of the variance in the low-dimensional space can remain challenging. Understanding the loadings and interpreting the biplot is a must-know part for anyone who uses PCA. Here I will explain i) how to interpret the loadings for in-depth insights to (visually) explain the variance in your data, ii) how to select the most informative features, iii) how to create insightful plots, and finally how to detect outliers. The theoretical background will be backed by a practical hands-on guide for getting the most out of your data with pca.




