


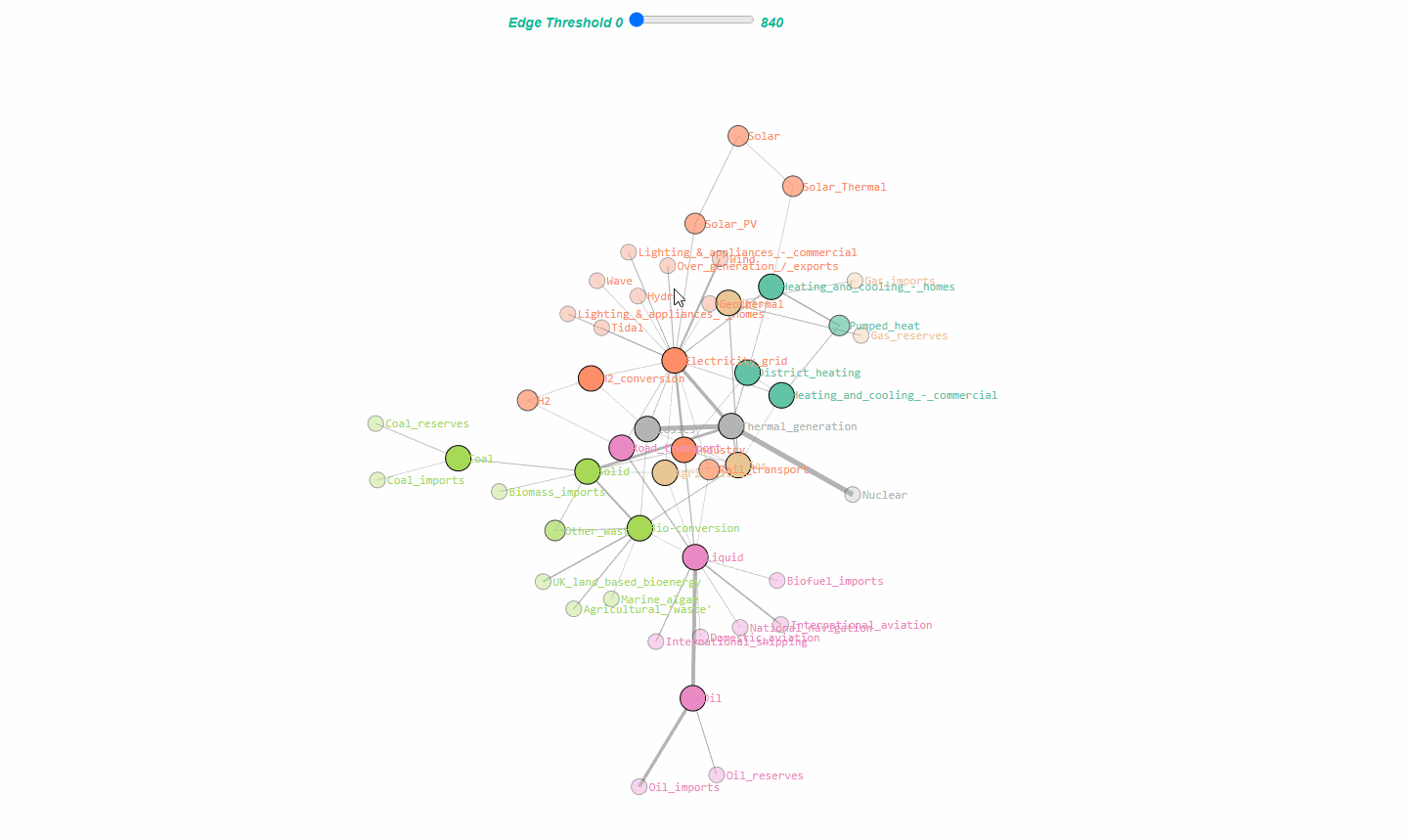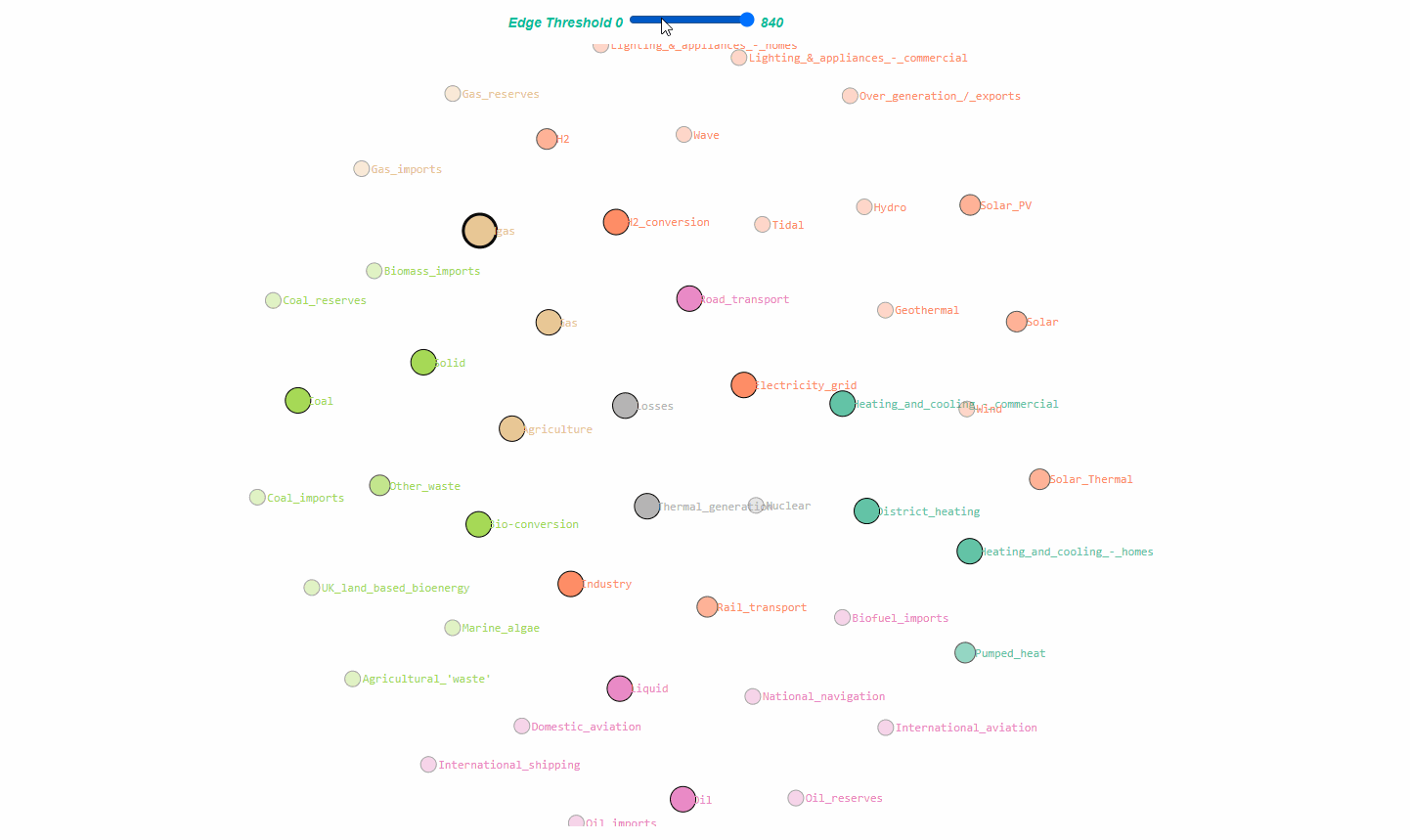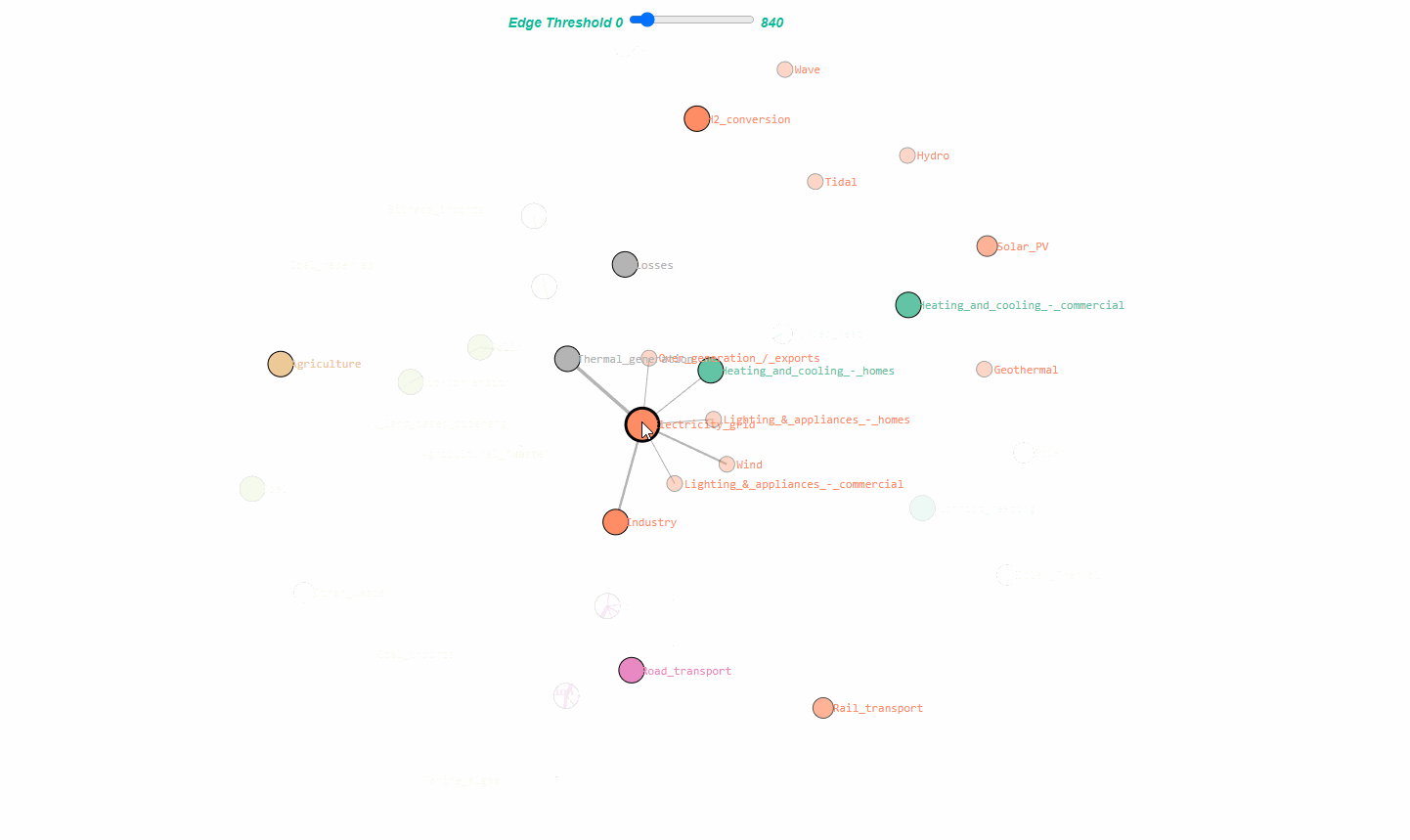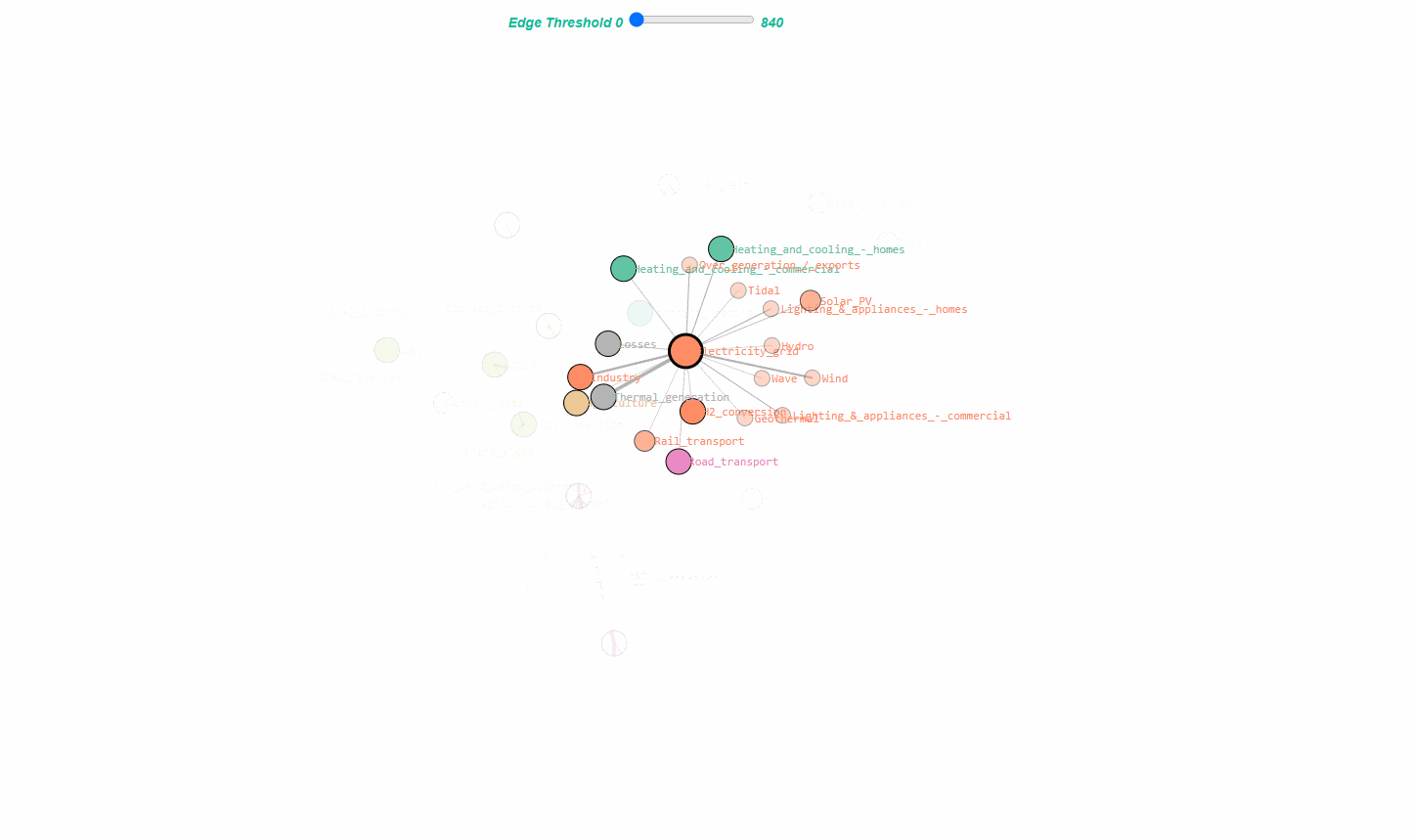
Understanding the strength of relationships between variables in a data set is important because variables with statistically similar behavior can affect the reliability of models. To detect the relationships between features and remove the so-called multicollinearity we can use correlation measures for continuous variables. However, when we also have categorical variables and thus mixed data sets, it becomes even more challenging to test for multicollinearity. Statistical tests, such as Hypergeometric testing and the Mann-Whitney U test can be used to test for associations across variables in mixed data sets. Although this is great, it requires various intermediate steps such as the typing of variables, one-hot encoding, and multiple test corrections, among others. This entire pipeline is readily implemented in a method named HNet. In this blog, I will demonstrate how to detect variables with similar behavior so that multicollinearity can be easily detected.




